最近参与的医学场景的项目中,模型的评价指标之一是AUC。
要讲清楚这个指标,需要首先了解一个评价模型的经典工具:混淆矩阵。
混淆矩阵 —— 模型能不能“明辨是非”
基础定义
我们训练AI模型,一个典型的任务是去预测一个事情是否会发生。
那医学场景举个例子:
-
我们给模型输入过去手术的数据,让它学习其中的特征。
-
我们的目的是希望训练后的模型在接受一段时间的手术数据输入后,给出未来一定时间内发生某类异常事件的可能性。
那么如何评价这个模型做的好不好呢?简单来说,需要记录预测结果与实际情况是否一致。我们定义:
-
预测结果
-
预测为正例(Positive, P)
-
预测为负例(Negative, N)
-
-
实际情况
-
实际为正例
-
实际为负例
-
对于这四种情况排列组合,我们就会得到一个模型的混淆矩阵(Confusion Matrix):
| 预测为正例 P | 预测为负例 N | |
|---|---|---|
| 实际为正例 | TP(True Positive) | FN(False Negative) |
| 实际为负例 | FP(False Positive) | TN(True Negative) |
对于矩阵的四个象限,其含义分别为:
| 缩写 | 含义 | 场景 |
|---|---|---|
| TP | 预测为正,实际为正 | ✅ 正确识别阳性(如:有异常事件有警报) |
| TN | 预测为负,实际为负 | ✅ 正确识别阴性(如:无异常事件无警报) |
| FP | 预测为正,实际为负 | ❌ 误报(如:无异常事件有警报) |
| FN | 预测为负,实际为正 | ❌ 漏报(如:有异常事件无警报) |
这里我经常搞糊涂,Positive和Negative分别对应的是预测的情况。预测为正例,指预测内容为事件发生,在混淆矩阵中标记为P,反之为N。
但与预测情况相对的,实际情况为正例,并不意味着对应情况记作T。
事实上,当实际情况与预测内容相匹配时,才会记为T;反之即为F。
也就是说,T 和 F 并不是标记实际情况中事件是否发生,而是表示实际情况与预测内容是否一致。
由混淆矩阵派生的关键指标
在实践中,混淆矩阵中的TP、FN、FP、TN通常是记录测试模型时,符合对应情况的测试样本数量。
比如说我们训练好了模型,测试时我们输入了1000个样本,结果分别为:
-
400个样本被预测为会发生异常事件
- 其中150个样本真的发生了异常事件,250个样本没有发生异常事件
-
600个样本被预测为不发生异常事件
- 其中50个样本真的发生了异常事件,550个样本没有发生异常事件
此时,这个模型的混淆矩阵可以记为:
| 预测为正例 P | 预测为负例 N | 总计 | |
|---|---|---|---|
| 实际为正例 | TP=150 | FN=50 | 200 |
| 实际为负例 | FP=250 | TN=550 | 800 |
| 总计 | 400 | 600 | 1000 |
那么针对这些数据,我们设计了许多指标来量化模型的质量:
准确率(Accuracy)
$$ \frac{TP+TN}{TP+TN+FP+FN} $$这个指标描述了所有样本中,模型预测正确的比例。
这是最直接的衡量模型的指标,可以对模型的整体性能做一个快速评估。
计算可得,上面模型的准确率为:$\frac{150+550}{1000}=0.7$
但这并不是完美的指标,当类别不平衡时会严重失真
比如说,1000个样本中,实际发生异常事件的只有10个(1%),无异常事件的有990个(99%),这是一种极端的事件分布,异常事件的出现概率很小。
此时,如果有一个”傻瓜“模型,它对所有样本都预测无异常事件。这时的Accuracy达到了惊人的99%。但这明显是没有意义的,模型实际上没有完成我们希望的任务。
精确率(Precision)
$$ \frac{TP}{TP+FP} $$这个指标描述的是,模型预测为正的样本中,有多少是真正为正的,因此也叫查准率。
对于一个高精确率的模型,意味着它的误报(FP)少,模型预测说会发生异常,那么大概率会发生异常。
反之,一个低精确率的模型则是经常搞”狼来了“,明明没有异常,却说有异常,这显然是不好的。
计算得到精确率为:$\frac{150}{150+250}=0.375$
召回率(Recall)
$$ \frac{TP}{TP+FN} $$这个指标描述了,实际为正的样本中,模型正确预测出来的样本占的比例,也叫查全率、灵敏度
一个高召回率的模型,意味着它的漏报(FN)少,模型能够捕捉到几乎所有的异常事件。
反之,则说明模型会有盲区,一部分异常事件会捕捉不到。
计算得到召回率为:$\frac{150}{150+50}=0.75$
F1-Score
$$ 2 \times \frac{Precision \times Recall}{Precision + Recall} $$这是精确率和召回率的调和平均,综合衡量模型性能。
调和平均:对低值更敏感,强制要求两者都高
以防你忘记什么是调和平均:
$$ > > \frac{2}{\frac{1}{a}+\frac{1}{b}}=\frac{2ab}{a+b} > > $$算术平均:会被高值主导,比如说精确率和召回率分别为100%与0%(极端一些,实际不会出现这种情况),算术平均为50%,但模型明显是不可用的。
F1-Score 避免了选择Precision和Recall的权衡困扰,因此比较模型时,用 F1-Score 是个好选择。
计算可得:$F1=2 \times \frac{0.375 \times 0,75}{0.375+0.75}=0.5$
ROC——不同阈值下模型的权衡能力
ROC(Receiver Operating Characteristic,接收者操作特征曲线),它是评估二分类模型的核心工具之一。
在解释ROC之前,我们先来聊聊模型分类的阈值。还是回到医学场景,我们的模型一般直接输出的是0~1之间的小数,表示当前样本中可能发生异常事件的概率值。
问题来了,概率值是多少时,我们认为这个会发生异常事件呢?
也就是说,我们需要给定一个阈值。当概率值>阈值时,预测为正例;反之,预测为负例。
这意味着,一个模型中预测正负例分别的数量会与阈值息息相关,我们取不同的阈值,可以计算出不同的TP、FP、TN、FN,进而计算不同的指标。
借助这一点,我们可以通过绘制ROC图来描述不同阈值下模型的能力。
-
X轴:假正率 FPR = FP/(FP+TN),实际为负例的样本中模型预测为正的比例
-
Y轴:真正率 TPR = TP/(TP+FN) = Recall,实际为正例的样本中模型预测为正的比例
-
对于一个模型测试的数据,我们取不同的阈值,可以分别算出多个 (FPR, TPR),作为横纵坐标的位置,画在图中并连线,就得到了ROC图
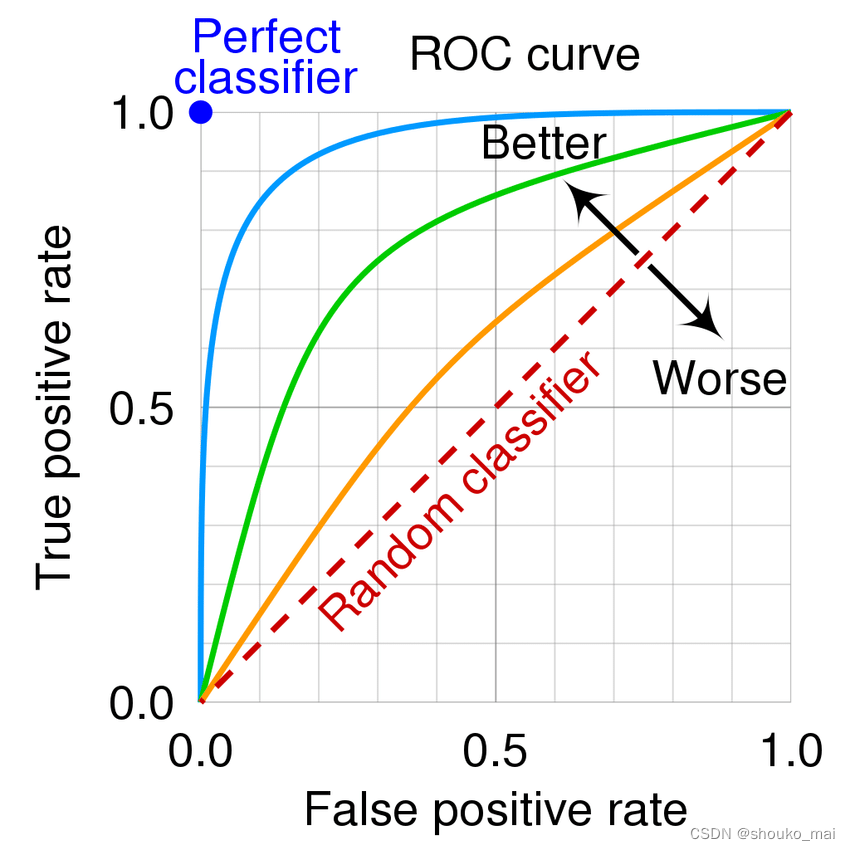
根据前面的定义,我们可以得到ROC的一些特征:
-
ROC图横纵坐标都局限在 [0, 1] 上
-
阈值定的很低时,模型不管怎么输出,都被认为预测为正例,此时横纵坐标均为1,(1, 1)
-
阈值定的很高时,模型不管怎么数据,都被认为预测为负例,此时横纵坐标均为0,(0, 0)
图中有一条直线,表示随机猜测(Random Classifier),顾名思义,就是模型随机输出预测概率,那么预测正确与错误的概率应该是相同的,ROC图就是一条y=x的直线。
一般来说,一个训练好的模型一般是在这条直线上方的,越远离这条线,说明模型性能越好,反之越差。
最理想的状态,我们希望模型假正率为 0% 的同时,预测正确的概率为 100% 。
ROC图足够直观,我们从其中提取出了一个量化指标:AUC值
AUC
定义
简单来说,AUC就是ROC曲线下的面积,取值为 [0,1]。
可以发现,AUC值的大小不依赖于特定的阈值,适合评估模型整体性能,且对类别不平衡的情况不敏感。
AUC值方便对比模型之间的性能,我参与的医学场景项目中,AUC就是衡量我们模型性能的一个重要指标。
AUC的概率解释
AUC的值可以理解为一个概率:
随机抽取一个正样本与一个负样本,模型给正样本打的分高于负样本的概率
(“打分”指的就是样本输入模型后,模型输出的值,即模型预测当前样本为真的概率)
我们来根据实际数据理解一下:
| AUC | 意味着 | 实际体验 |
|---|---|---|
| 1.0 | 正样本的分数永远排在负样本前面 | 随便设个阈值都能完美分离 |
| 0.9 | 90% 的正样本分数更高 | 偶尔有"难例"混淆,但总体可靠 |
| 0.7 | 70% 的正样本分数更高 | 正负有相当重叠,需要谨慎选阈值 |
| 0.5 | 和随机猜一样 | 模型完全没学到特征,在它眼中正负样本没有区别 |
局限性
AUC并不反映精确率,或者说查准率。我们可以结合 PR曲线。
下面通过一个案例来具体说明ROC图的应用:
案例:垃圾邮件识别
我们规定:
-
正例(1):认为是垃圾邮件
-
负例(0):认为是正常邮件
现在我们创建1000条模拟数据如下:
| 类别 | 数量 | 模型预测概率分布 |
|---|---|---|
| 垃圾邮件(正例) | 100 封 | 90封高概率(0.8-0.95),10封低概率(0.1-0.3) |
| 正常邮件(负例) | 900 封 | 50封高概率(0.6-0.75),850封低概率(0.05-0.2) |
下面是在一种可能的分布下,不同阈值对应的混淆矩阵:
| 阈值 | 预测规则 | TP | FP | TN | FN | TPR | FPR | Precision |
|---|---|---|---|---|---|---|---|---|
| 0.9 | 极严格 | 60 | 5 | 895 | 40 | 60% | 0.6% | 92.3% |
| 0.7 | 严格 | 80 | 15 | 885 | 20 | 80% | 1.7% | 84.2% |
| 0.5 | 平衡 | 90 | 35 | 865 | 10 | 90% | 3.9% | 72.0% |
| 0.3 | 宽松 | 95 | 80 | 820 | 5 | 95% | 8.9% | 54.3% |
| 0.1 | 极宽松 | 99 | 200 | 700 | 1 | 99% | 22.2% | 33.1% |
我们可以对此画一个ROC图并计算AUC值:
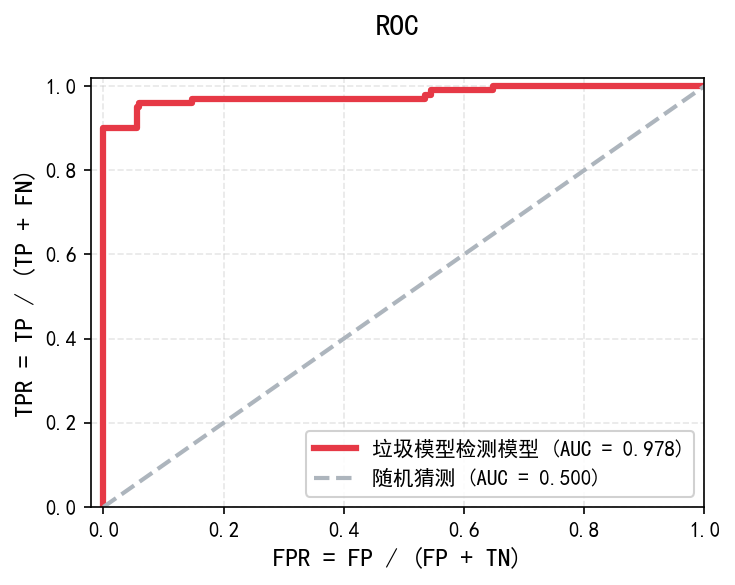
画图和模拟数据的代码见下:
|
|